Lessons learned
Linear Regression:
- Trying to fit data into a polynomial theta*x
- The cost function

- Gradient descent update of the theta
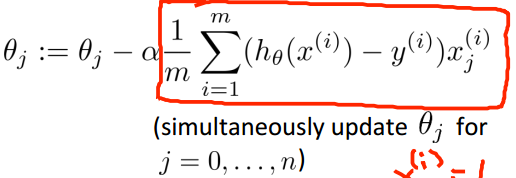
Logistic regression:
- Classification of data
- Cost function

- Logistic function
- Gradient descent update
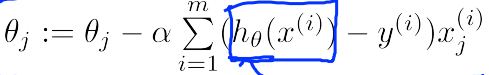
Regularization
- To prevent overfitting
- Linear regression cost function

- Gradient descent
- Logistic regression cost function
- Steepest descent update
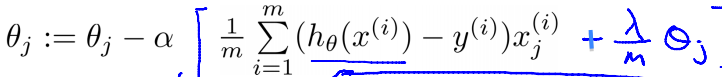
Neural networks
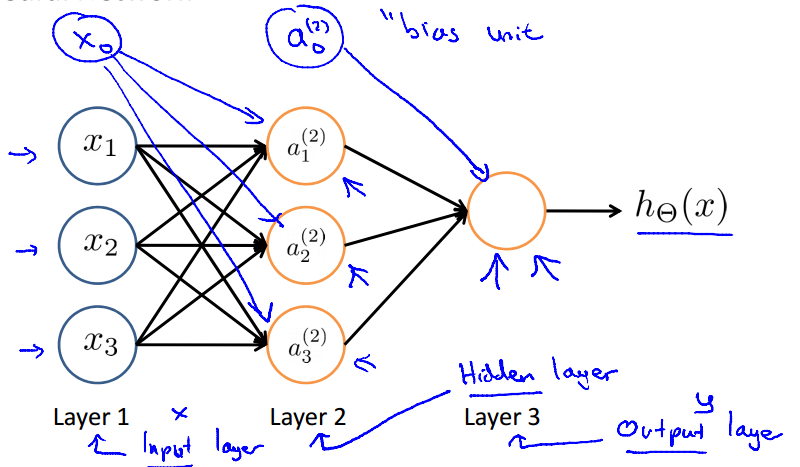

- Cost function

Backpropagation
- Starting with the error of the output layer, propagate backwards to find error of each layer to compute the gradient


- It is easy to make a mistake in estimating the gradient, hence one can check the gradient every several hundred iterations to make sure its falling down. Cross check function (slow)
- Thetas should be randomly initialized but NOT zero
- Summary:



Diagnostics
- Split data to 60% training 20% Cross validation and 20% test
- Use different parameters of the algorithm (Number of features, polynomial orders, regularization parameters) on the training set.
- Choose the one which minimizes the Cross Validation set error
- Generalize on the test set

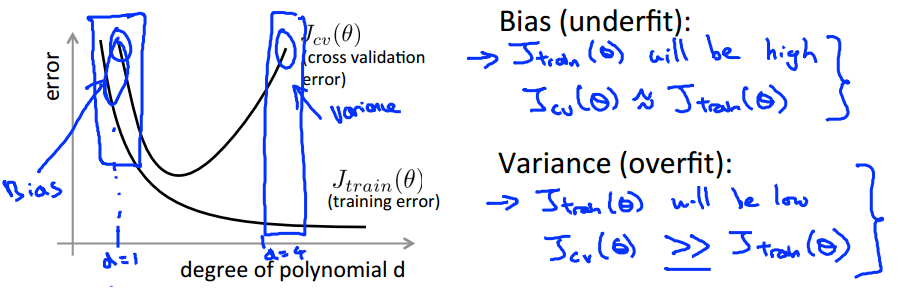


- Bias and variance


- Summary of diagnostics

SVM
Linear Kernel
- Cost function

- With cost defined as

Gaussian Kernel
- Distance between each point and training set is considered a ‘feature’


- Overfitting with Gaussian Kernels

Logistic vs SVM vs Neural network

Unsupervised learning
K means

- Random initialization of the centroids can be done by picking up data points. We can try 100 random initializations and get the one with the lowest cost

Dimensionality reduction using PCA
- Data must be normalized first
- Compute covariance matrix

- Compress your data

- K should be chosen so that

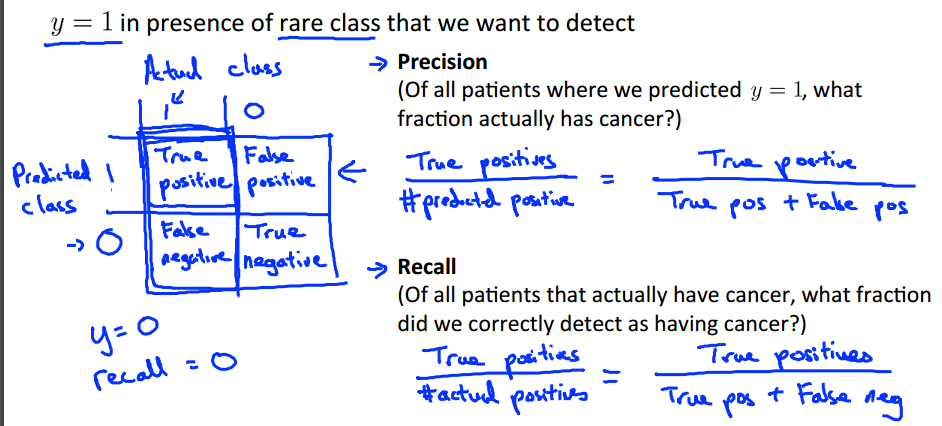
Precision/Recall

Online learning
- As a data set arrives, update gradient descent to get new theta

MapReduce
- Distribute tasks over separate cores/computers to perform the task and combine them at the end

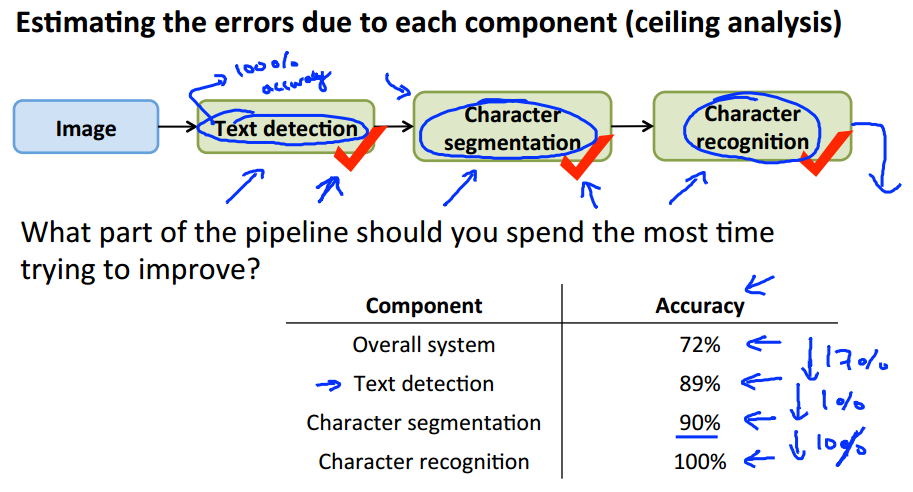
- To check which part of the pipeline to be investigated better do a ceiling analysis


No comments:
Post a Comment