Lessons learned
- Spark is a framework which can manage hadoop clusters in a more efficient way than MapReduce
- Scala is a programming language which fits into big data. It is similar to java
- Spark can work with Python Java or Scala, Python is easy but sometimes is slower than Scala, besides Scala is closer to implementation.
- Installation is tricky, what needs to be installed is
- Java JDK install http://www.oracle.com/technetwork/java/javase/downloads/index.html (go thru installation)
- Winutils.exe (just a file)
- Scala IDE (preinstalled)
- Problems encountered:
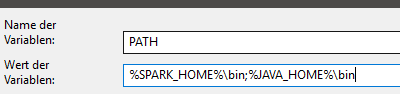
- Environment variable of Java has to be written as PROGRA~1 instead of program files

- Make sure scala version is correct, right click on the project -> Scala -> Set the scala installation

- When running the configurations, make sure com.sundogsoftware.SPARK.xxxx
- Concept of spark is similar to hadoop. A driver program with a spark contrext manages worker nodes
- Scala crash course
- Variable initialization val name: type = value;

val numberOne : Int = 1 //> numberOne : Int = 1
val truth : Boolean = true //> truth : Boolean = true
val letterA : Char = 'a' //> letterA : Char = a
val pi : Double = 3.14159265 //> pi : Double = 3.14159265
val piSinglePrecision : Float = 3.14159265f //> piSinglePrecision : Float = 3.1415927
val bigNumber : Long = 1234567890l //> bigNumber : Long = 1234567890
val smallNumber : Byte = 127 //> smallNumber : Byte = 127
- Printing out can be done with specific precision
println(f"Pi is about $piSinglePrecision%.3f") //> Pi is about 3.142
- Pad zeros on the left
println(f"Zero padding on the left: $numberOne%05d")
- Variables can be printed with $name
println(s"I can use the s prefix to use variables like $numberOne $truth $letterA")
- Expressions can be evaluated between curly brackets
println(s"The s prefix isn't limited to variables; I can include any expression. Like ${1+2}")
- Regular expressions can be evaluated with .r after the string
val theUltimateAnswer: String = "To life, the universe, and everything is 42."
//> theUltimateAnswer : String = To life, the universe, and everything is 42.
//|
val pattern = """.* ([\d]+).*""".r //> pattern : scala.util.matching.Regex = .* ([\d]+).*
val pattern(answerString) = theUltimateAnswer //> answerString : String = 42
val answer = answerString.toInt //> answer : Int = 42
println(answer) //> 42
- For loops uses x <- 1 to 4
for (x <- 1 to 4)
- Functions are defined as def <function name>(parameter name: type...) : return type = { expression }
def squareIt(x: Int) : Int = {
x * x
}
- Tuples
val captainStuff = ("Picard", "Enterprise-D", "NCC-1701-D")
//> captainStuff : (String, String, String) = (Picard,Enterprise-D,NCC-1701-D)
//|
println(captainStuff) //> (Picard,Enterprise-D,NCC-1701-D)
// You refer to individual fields with their ONE-BASED index:
println(captainStuff._1) //> Picard
println(captainStuff._2) //> Enterprise-D
println(captainStuff._3) //> NCC-1701-D
Lists
val shipList = List("Enterprise", "Defiant", "Voyager", "Deep Space Nine")
//> shipList : List[String] = List(Enterprise, Defiant, Voyager, Deep Space Nin
//| e)
// Access individual members using () with ZERO-BASED index (confused yet?)
println(shipList(1)) //> Defiant
// head and tail give you the first item, and the remaining ones.
println(shipList.head) //> Enterprise
println(shipList.tail) //> List(Defiant, Voyager, Deep Space Nine)
- Iterate through list
for (ship <- shipList) {println(ship)}
- Map changes each member of list to another value
- We can apply function literals to each value in a list
val backwardShips = shipList.map( (ship: String) => {ship.reverse})
- Reduce defines how each RDD element of the clusters are combined together
val sum = numberList.reduce( (x: Int, y: Int) => x + y)
- Filter picks up only the values which fit to a certain criteria
val iHateFives = numberList.filter( (x: Int) => x != 5)
- Lists can be concatenated with ++
val lotsOfNumbers = numberList ++ moreNumbers
- List operations
// More list fun
val reversed = numberList.reverse //> reversed : List[Int] = List(5, 4, 3, 2, 1)
val sorted = reversed.sorted //> sorted : List[Int] = List(1, 2, 3, 4, 5)
val lotsOfDuplicates = numberList ++ numberList //> lotsOfDuplicates : List[Int] = List(1, 2, 3, 4, 5, 1, 2, 3, 4, 5)
val distinctValues = lotsOfDuplicates.distinct //> distinctValues : List[Int] = List(1, 2, 3, 4, 5)
val maxValue = numberList.max //> maxValue : Int = 5
val total = numberList.sum //> total : Int = 15
val hasThree = iHateThrees.contains(3) //> hasThree : Boolean = false
- Map is a form of Key Value pair
val shipMap = Map("Kirk" -> "Enterprise", "Picard" -> "Enterprise-D", "Sisko" -> "Deep Space Nine", "Janeway" -> "Voyager")
- Can access a value through its key
println(shipMap("Janeway")) //> Voyager
- .contains checks if a value is present
println(shipMap.contains("Archer")) //> false
- Catch errors
val archersShip = util.Try(shipMap("Archer")) getOrElse "Unknown"
- Handle character encoding issues
codec.onMalformedInput(CodingErrorAction.REPLACE)
codec.onUnmappableCharacter(CodingErrorAction.REPLACE)
- Operations of RDDs are divided into: 1. Transformations 2. Actions
- OPERATIONS WILL NOT TAKE EFFECT BEFORE TAKING ACTION (REDUCE). ONLY THEN SPARK FINDS THE OPTIMUM WAY TO SET THE STAGES OF MAPREDUCE
- First step is creating a spark context. local[*] is only for running on a single node.




val sc = new SparkContext("local[*]", "RatingsCounter")
- Reading a text file
val lines = sc.textFile("../ml-100k/u.data")
- Parsing text is a common function
def parseLine(line: String) = {
// Split by commas
val fields = line.split(",")
// Extract the age and numFriends fields, and convert to integers
val age = fields(2).toInt
val numFriends = fields(3).toInt
// Create a tuple that is our result.
(age, numFriends)
}
- To apply the parseLine function to the map use
val rdd = lines.map(parseLine)
- SQL and Dataframes are a structured way to store data.
- It can interact with JSON and SQL databases
- We initialize SparkSession instead of SparkSession. Make sure C./temp is there
- // Use new SparkSession interface in Spark 2.0
- val spark = SparkSession
- .builder
- .appName("SparkSQL")
- .master("local[*]")
- .config("spark.sql.warehouse.dir", "file:///C:/temp") // Necessary to work around a Windows bug in Spark 2.0.0; omit if you're not on Windows.
- .getOrCreate()
- Loading files is done as
- val lines = spark.sparkContext.textFile("../fakefriends.csv")
- Data is mapped using a mapper with a specific object which can take different data types
- case class Person(ID:Int, name:String, age:Int, numFriends:Int)
- def mapper(line:String): Person = {
- val fields = line.split(',')
- val person:Person = Person(fields(0).toInt, fields(1), fields(2).toInt, fields(3).toInt)
- return person
- }
- To convert to dataset, must first import a library
- val people = lines.map(mapper)
- import spark.implicits._
- val schemaPeople = people.toDS
- Operations of DataFrames
- Selecting a certain column with name
- people.select("name").show()
- Filter objects in a column
- people.filter(people("age") < 21).show()
- Group all keys then count them in a single row
- people.groupBy("age").count().show()
- Key Pair operations
- Time series
- To process data based on previous values
- General article
- 2 steps
- Create a window spec :
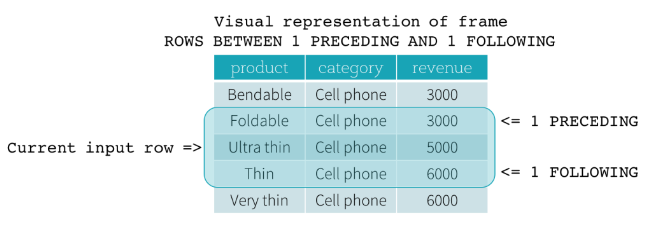
val wSpec1 = Window.partitionBy(“name”).orderBy(“date”).rowsBetween(-1, 1)
rowsBetween defines the window of operations on the current row - Do the operation:
customers.withColumn( “NewColumnName”, avg(customers(“nameOfColumnToOperateOn”)).over(wSpec1) ).show() - Operations;
- Avg : simple average
- Sum: sum
customers.withColumn( “cumSum”, sum(customers(“amountSpent”)).over(wSpec2) ).show() - Lag: data from the previous row
customers.withColumn(“prevAmountSpent”, lag(customers(“amountSpent”), 1).over(wSpec3) ).show() - Rank: number of occurrences so far
customers.withColumn( “rank”, rank().over(wSpec3) ).show()




- Machine learning
- Read chapter of the book learning spark about machine learning
- Example file: MovieRecommendationsALS.scala
- There are special data types for MLLIB
- General structure
- Regression; LinearRegressionDataFrame.scala
- Must first create a Spark session
- val spark = SparkSession
- .builder
- .appName("LinearRegressionDF")
- .master("local[*]")
- .config("spark.sql.warehouse.dir", "file:///C:/temp") // Necessary to work around a Windows bug in Spark 2.0.0; omit if you're not on Windows.
- .getOrCreate()
- RDD has to be set to the format [label, Vectors]
- val data = inputLines.map(_.split(",")).map(x => (x(0).toDouble, Vectors.dense(x(1).toDouble)))
- Convert to DataFrame while giving names to each column
- import spark.implicits._
- val colNames = Seq("label", "features")
- val df = data.toDF(colNames: _*)
- Split data to training and testing (cross validation)
- // Let's split our data into training data and testing data
- val trainTest = df.randomSplit(Array(0.5, 0.5))
- val trainingDF = trainTest(0)
- val testDF = trainTest(1)
- Linear regression model
- val lir = new LinearRegression()
- .setRegParam(0.3) // regularization
- .setElasticNetParam(0.8) // elastic net mixing
- .setMaxIter(100) // max iterations
- .setTol(1E-6) // convergence tolerance
- Fit data
- val model = lir.fit(trainingDF)
- Perform prediction
- val fullPredictions = model.transform(testDF).cache()
- Obtain predictions column
- // Extract the predictions and the "known" correct labels.
- val predictionAndLabel = fullPredictions.select("prediction", "label").rdd.map(x => (x.getDouble(0), x.getDouble(1)))
- Must close the session!
- spark.stop()
- Date processing:
- Use the function unix_timestamp which returns seconds




No comments:
Post a Comment